Faculty Mentor:
Dr. Deepti Sharma
Student Name:
Latika Malhotra (MCA-II)
Ashima Tyagi (MCA-II)
1. INTRODUCTION
The evolution of information technology and the use of smart phones expanded the availability of information. Plagiarism is usually defined as ‘‘the wrongful appropriation" and "stealing and publication" of another author's "language, thoughts, ideas, or expressions" and the representing them as one's own original work.’’ [1]
And moreover, according to the Merriam-Webster Online Dictionary, to “plagiarize” means:
– “To steal and pass off the ideas of another as one’s own.”
– “To present as new and original an idea derived from an existing source.”
– “To use someone’s production and not crediting the source.”
– “To commit literary theft.”
Plagiarism can be categorized into five divisions: Copy & Paste Plagiarism, Idea Plagiarism, Word Switch Plagiarism, Style Plagiarism Metaphor Plagiarism, and Idea Plagiarism [2].
Although with the advancing minutes the techniques to plagiarize are experiencing many new variations but, the two most popular ones are still intact in public’s mind:
1. Textual plagiarisms: committed most frequently by researchers and students in academic enterprises, this sort of plagiarism leads the documents to be totally identical to the original documents, reports and scientific papers.
2. Source code plagiarism: frequently committed by students of universities, this sort of plagiarism is done while attempting or copying the whole or some segments of that specific source code created by someone else as his own, the ordinary feature of this plagiarism leads it to being hardly detected.
There are many variants of plagiarism detection process. Among them, a few are- “textual based plagiarism, citation based plagiarism, and shape based plagiarism for flowchart”
[3]. Textual plagiarism is a name given to the plagiarism which takes place if the original text is copied, with small alterations or if it’s translated by machines. However, when the translation of this text is done by humans then currently used techniques have very little means to detect it. Plagiarism Detection based on citation on the other end of the spectrum, assimilates the occurrences of citations in order to identify the similarities. Meanwhile, plagiarism based on shape for the purpose of flowchart showcases a technique for detecting multimedia retrieval and image processing. But, it is still not able to recognize plagiarism for varying charts and figures along with their contents.
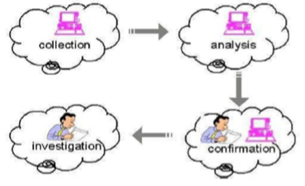
Fig. 1 Four-stage Plagiarism Detection Process [2]
1.1. Text Based Plagiarism
This sort of plagiarism deals with the detection of similarities between documents with the help of vector space model. Moreover, it has the ability to count and calculate the redundancy of the term in the document, and from that point they match the document’s fingerprints with fingerprints from other documents and find the parallelism between them. This methodology is appropriate for non-partial plagiarism as described above, it uses the complete document and takes help of vector space to match between the documents, but if the document has been partly plagiarized it yields very poor results. It includes “copy and paste”, “modification or changing some words of the original information from the internet book magazine”, “newspaper, research, journal, personal information or id0eas” [5].
1.1.1. Process of plagiarism based on text is divided into the following stages: -
1. Stage One Collection: First stage of Plagiarism Detection Process involves “the student or the researcher to upload their assignments or works to the web engine, the web engine acts as an interface between the students and the system.”
2. Stage Two Analysis: Second stage entails that submitted corpus or assignments are run through a similarity detecting engine to check whether documents are similar to other ones or not. There are two categories of similarity engines, first intra-corpal engine and second extra-corpal engine. “The intra-corpal engines work by returning ordered list between each similar pairs.
3. Stage Three Confirmations: This stage functions to identify if some specific relevant text has been copied from original text or to adjudge if there is a high rate of similarity between any other text and the source text.
4. Stage Four Investigation: This is the final stage of a Plagiarism Detection Process and it relies on human intervention. In this step a human expert is responsible for determine if the system ran correctly as well as determining if a result has been truly plagiarized or simply cited. [2]
1.1.2. Different methods used for textual plagiarism detection
The most prevalent form of plagiarism among high school students is taking phrase word by word or taking entire source without adding quotation marks and even not citing it properly. The Internet has made copy & pasting extremely tempting for students’ common plagiarism detection techniques rely on character-based methods to compare the suspected document with original document. Character matching approaches can detect identical strings.
Following are the two methods for textual plagiarism detection.
1.1.2.1. Grammar-based method: The grammar-based method is an important tool to detect plagiarism. It focuses on the grammatical structure of documents, and this method uses a string-based matching approach to detect and to measure similarity between the documents. The grammar- based methods are suitable for detecting exact copy without any modification, but it is not suitable for detecting modified copied text by rewriting or switching some words that has the same meaning. This is considered as one of this method’s limitations.
1.1.2.2. External plagiarism detection method: It basically depends on a reference corpus composed of documents from which passages might have been plagiarized. A suspicious document is checked for plagiarism by searching for passages that are duplicates. Then a report is sent by the external plagiarism system to these findings to a human controller who is responsible for deciding whether the detected passages are plagiarized or not. [5]
Fig 2: SHAPE-BASED PD for flowchart [5]
1.2. Citation-Based Plagiarism
“Citation-based Plagiarism Detection (CbPD) subsumes methods that use citations and references for determining document similarities in order to identify plagiarism” [4]. In the academic environment citations and references of scholarly publications have long been recognized for containing valuable semantic information about the content of a document and its relation to other works. The degree of similarity between citation patterns depends mainly on the amount of shared references and the extent to which the order of included citations.
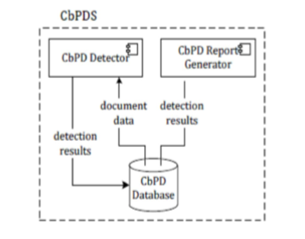
Fig. 3 CbPDS system architecture [3]
1.2.1. Identifying Citation Patterns
Citation finds similar pattern which is generally used with two scientific texts is a strong indicator for semantic text similarity and the core idea of CbPD. Patterns are subsequences in the citation tuples CA and CB of two texts A and B that consist of shared references and that is why they are similar to each other. The degree of similarity between patterns depends on the number of citations included in the pattern, and the extent to which their order and/or the range they cover is alike. Thus, literally matching subsequences of citations in two documents is a strong indicator for semantic similarity. [3]
1.2.2 Unknown pattern constituents:
Original: 1 2 3 x x x 4 x x 5 x 6 x 7 8
Plagiarism: x x 5 x x x 4 x 3 x 1 x 2 x x 7 x 8
2. PLAGIARISM DETECTION
Plagiarism can occur between two same or two different natural languages. Based on language homogeneity or heterogeneity of the textual documents being compared, the plagiarism detection can be divided into two basic types [6] i.e., monolingual and cross-lingual.
2.1. Monolingual Plagiarism Detection: This type of detection deals with homogeneous language settings e.g., English-English. Most detection methods are of this category. It can be further divided into two subtypes based on the use of external references during detection.
2.1.1 Intrinsic Plagiarism Detection: It analyses the writing style or uniqueness of the author and attempts to detect plagiarism based on own conformity or deviation between the text segments. It does not require any external sources for detection.
2.1.2 Extrinsic Plagiarism Detection: Unlike the intrinsic approach, in this a submitted research article is compared against many other available relevant digital resources in repositories or in the Web for detection of plagiarism.
2.2. Cross-Lingual Plagiarism Detection: This detection approach is able to perform in heterogeneous language settings e.g., English-Chinese. Few cross-lingual plagiarism detection methods are available due to difficulty in finding proximity between two text segments for different languages.
3. SOFTWARE BASED PLAGIARISM DETECTION TOOLS
Many software systems are available that suggest that they can reliably determine if a submitted text or an online document is plagiarized or not. Software can only hope to compare the syntax, on a character or word level, and determine the similarity between texts. There is some experimental work being done in the area of semantic recognition. But this only seems successful in the area of highly structured text such as program language code. [5]
3.1. PlagAware: Is a search engine, that is the main element and is strong in detecting typical contents of given texts. Classical search engine is used for detecting and scanning plagiarism, and provide different types of reports that help the user or the document owner to decide that his document has been plagiarized or not. Is an online-service used for textual plagiarism detection, which allows and offers some services for the user for example can search, find, analyze and trace plagiarism in the specified topic similar to the topics? (web link: https://www.plagaware.com)
3.2. PlagScan PlagScan: is an online software used for textual plagiarism checker. It is often used by schools for providing different types of account with different features. Complex algorithms are used by PlagScan for checking and analyzing uploaded document for plagiarism detection, based on up-to-date linguistic research. Unique signature extracted from the document’s structure that is then compared with PlagScan database and millions of online documents. (Web link : https://www.plagscan.com/en/)
3.3. CheckForPlagiarism.net: It was developed by a team of professional academic people and became one of the best online plagiarism checkers. It is basically used for the prevention of online plagiarism. To maximize the accuracy, it has used some methods like document fingerprint and document source analysis to protect document against plagiarism. (Web link: https://www.checkforplagiarism.net/)
3.4. iThenticate: It is designed especially for the researchers, authors’ publisher and other. It is designed to be used by institutions rather than personal, but lastly they provided a limit service for single plagiarism detection user like master and doctoral students and also allows them to check a single document of up to 25,000 words. So they can use this service to insure or to check their draft thesis whether containing correct citation and content originality. (Web link: www.ithenticate.com/)
3.5 PlagiarismDetection.org: It is an online service that provides high level of accuracy that leads to plagiarism detection. It is designed to help the teachers and student to maintain or prevent and detect plagiarism against their academic documents. The plagiarism can be detected with high level of accuracy. (Web link: www.plagiarismchecker.net/plagiarism-detection-org-2-6.php )
3.6 Viper: This free plagiarism scanner scans the submitted documents against 10 billion sources and documents present in a computer. It gives peace of mind regarding any accidental plagiarism. This tool offers unlimited resubmitting of documents and it provides links to plagiarized work in the reports. (Web link: https://www.scanmyessay.com)
4. COMMON PROBLEMS & RESEARCH GAP
The common problem noted with most of these tools is their lack of ability to detect intelligent manipulations, even though they claim to be. Most of the tools, even paid, fail when it comes to translation and summary obfuscations. In today’s world, with the ease of access to online translation and summarization tools a plagiarist can easily perform intelligent and complex manipulations in source text which can surpass the detection capacity of these tools. Further the condition can be still complex when theses obfuscations are manually combined. Patents with efficient text plagiarism detection tools are not found while some for source code plagiarism were there. During the survey it was surprising to see that some accepted publications found in web were exact copies of original piece of work and even the citations to those works were not given in them. These scenarios cannot be treated as unintentional because some of the basic ethics of writings must be followed at least when publishing papers. One reason for the growth of this kind of work may be that either some journals or conferences do not employ any sort of plagiarism checking or the tools used are inefficient. Thus there is still a lot to explore and improve in this domain to improve the efficiency of detection tools. From analysis done with some of the available tools, it is clear that a lot has to be improved to tackle high obfuscation plagiarism cases. A lot of research gaps can be analyzed, mainly in:
4.1. Improving detection techniques mainly focusing on paraphrase and intelligent manipulation detection.
4.2. Structural and semantic variations or manipulations are least captured by the available tools. Thus algorithm efficiency should be improved in these terms.
4.3. Focusing on plagiarism using idea adoptions via, summary obfuscations which are hard to tackle. In these aspects computational intelligence, soft computing and advanced NLP techniques can be explored. From the literature, it is found most of the works done are with N-gram models, VSM etc. Only very few works with semantic and intelligent implementation were found.
4.4. Citation based techniques are very less explored and have good scope in facilitating the improvement of detection efficiency, when coupled properly with text based techniques.
4.5. Focus on candidate retrieval stage techniques, specifically when dealing with online resources. Techniques for query formulation and proper key phrase extractions have to be explored for regulating and improving the performance efficiency of a PDS.
These are some of the few research potentials that we came across during the studies and analysis.
5. CONCLUSION
This paper presents a brief review about the tools and techniques in extrinsic text plagiarism. It attempts to provide some insight to the current state of art in this domain, the techniques used, the tools etc. Study and analysis of some of the tools are done, further pointing the main problems with these tools and the research gaps Intelligent techniques for detection of high obfuscations are still in its infancy and most of the available online, stand alone and web based tools fail to detect complex manipulations. The paper thus throws light on the immense research potential in this field for developing efficient intelligent detection systems so as to curb this unethical act.
6. REFERENCES
1. Hermann Maurer, Frank Kappe, Bilal Zaka “Plagiarism - A Survey”, Institute for Information Systems and Computer Media Graz University of Technology, Austria, vol. 12, no. 8 2006.
2. Ahmed Hamza Osman, Naomie Salim1, and Albaraa Abuobieda, ”Survey of Text Plagiarism Detection”, International University of Africa, Faculty of Computer Studies, Khartoum, Sudan Vol. 1, No. 1, June 2012.
3. Bela Gipp OvGU, ”Citation-based Plagiarism Detection – Idea”, Implementation and Evaluation “Germany / UC Berkeley, California, USA 2010.
4. Bela Gipp, Norman Meuschke, Joeran Beel, “Comparative Evaluation of Text- and Citation-based Plagiarism Detection Approaches using GuttenPlag” ,Ottawa, Canada, June 13-17, 2011.
5. Asim M. El Tahir Ali, Hussam M. Dahwa Abdulla, “Overview and Comparison of Plagiarism Detection Tools“, Department of Computer Science, Germany & UC Berkeley JCDL 2011.
6. S. M. Alzahrani, N. Salim, A. Abraham, “Understanding plagiarism linguistic patterns, textual features, and detection methods”, IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews) 42 (2) (2012) 133-149.